Tout sous Linux est considéré comme un fichier pour maintenir la cohérence. Cela inclut les périphériques matériels, les imprimantes, les répertoires et les processus. Les fichiers normaux tels que la musique, le texte, les vidéos et autres fichiers multimédias ont également des données supplémentaires qui leur sont associées appelées métadonnées.
Que sont les inodes sous Linux? Les entrées d'inode sont la base du Système de fichiers Linux. Ils gèrent les métadonnées d'un fichier et sont des éléments essentiels du fonctionnement interne de Linux.

Quelle est la structure d'un système de fichiers?
Un système de fichiers est divisé en deux parties - blocs de données et inodes. Le nombre de blocs est fixé une fois créé et ne peut pas être modifié.
Le nom, le chemin, l'emplacement, les liens et les autres attributs de fichier ne se trouvent pas dans le répertoire. Les répertoires sont simplement des tableaux qui contiennent les noms des fichiers avec le numéro d'inode correspondant.
Vous pouvez créer un lien dur résultant en plusieurs noms pour le même fichier. Lorsque vous créez un lien dur, il crée également un nouveau nom dans la table avec l'inode mais ne déplace pas le fichier.
Si vous deviez déplacer un gros fichier, cela prendrait beaucoup de temps. Il est plus efficace de créer l'entrée de nom dans un nouveau répertoire et de supprimer l'ancienne entrée. Vous pouvez également renommer des fichiers de la même manière.
In_content_1 all: [300x250] / dfp: [640x360]->La partie supérieure de la hiérarchie est le système de fichiers lui-même. Dans le système de fichiers se trouvent les noms de fichiers. Les noms de fichiers sont liés aux inodes. Les inodes sont liés aux données physiques.
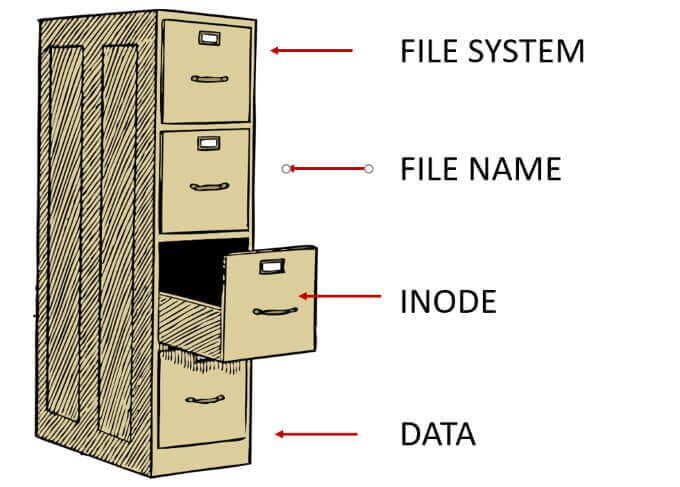
Que sont les inodes sous Linux?
Un inode est une structure de données. Il définit un fichier ou un répertoire sur le système de fichiers et est stocké dans l'entrée de répertoire. Les inodes pointent vers des blocs qui composent un fichier. L'inode contient toutes les données administratives nécessaires pour lire un fichier. métadonnées de chaque fichier est stocké dans des inodes dans une structure de table.
Lorsque vous utilisez un programme qui fait référence à un fichier par son nom, le système cherchera dans le fichier d'entrée de répertoire où il existe pour tirer l'inode correspondant. Cela donne à votre système les données de fichier et les informations dont il a besoin pour effectuer des processus ou des opérations.
Les inodes sont généralement situés près du début d'une partition. Ils stockent toutes les informations associées à un fichier, à l'exception du nom de fichier et des données réelles. Tous les fichiers de n'importe quel répertoire Linux ont un nom de fichier et un numéro d'inode. Les utilisateurs peuvent récupérer les métadonnées d'un fichier en référençant le numéro d'inode.
Les noms de fichier et les numéros d'inode sont stockés dans un index séparé et liés à l'inode. Vous pouvez créer un lien vers les métadonnées qui représentent le fichier. Il est possible d'avoir plusieurs noms de fichiers liés à une seule donnée ou inode comme vous pouvez le voir dans l'image ci-dessous.
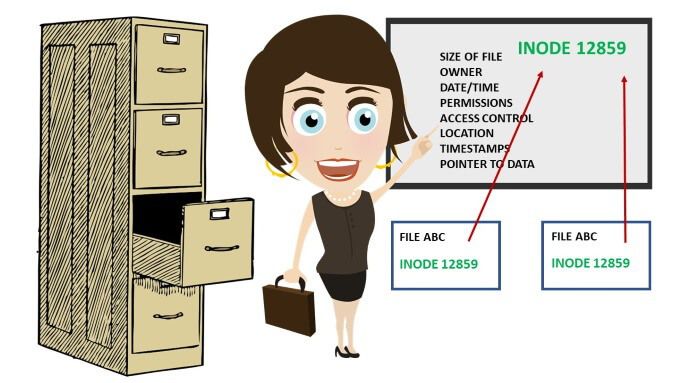
Qu'est-ce que le numéro d'inode?
Chaque inode de la structure Linux a un numéro unique identifié. Il est également appelé numéro d'index et possède les attributs suivants:
Pour vérifier la liste des numéros d'inode, utilisez la commande suivante:
ls -i
La capture d'écran ci-dessous montre un répertoire avec les numéros d'inode apparaissant dans la colonne la plus à gauche.
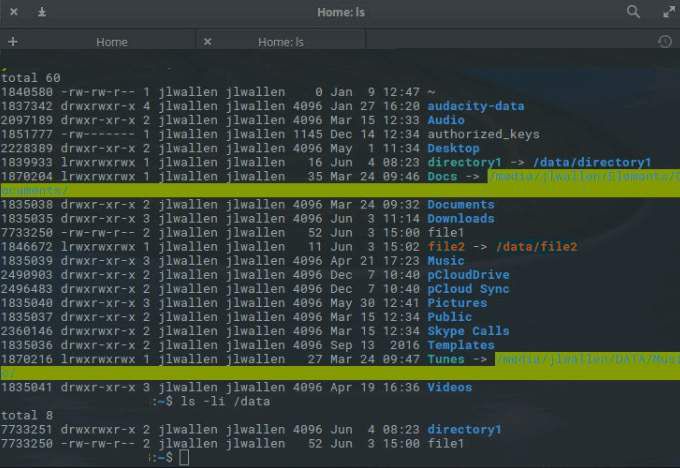
Comment fonctionnent les inodes?
Lorsque vous créez un nouveau fichier, un nom de fichier et un numéro d'inode lui sont attribués. Les deux sont stockés comme entrées dans un répertoire. L'exécution de la commande ls (ls -li) vous montrera une liste des noms de fichiers et des numéros d'inode qui sont stockés dans un répertoire.
Utilisez la commande ci-dessous pour répertorier les informations d'inode pour chaque système de fichiers.
df -hi
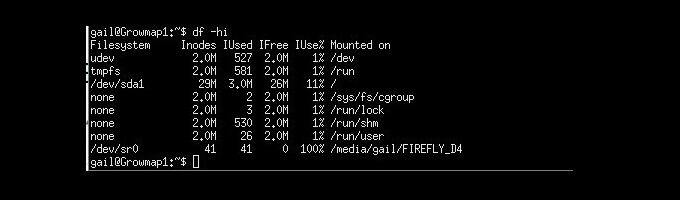
Combien d'inodes utilisez-vous?
Une façon de manquer d'espace dans un système de fichiers, c'est utiliser tous vos inodes. Même si vous avez suffisamment d'espace libre sur votre disque, vous ne pourrez pas créer de nouveaux fichiers.
L'utilisation de tous les inodes peut également entraîner l'arrêt soudain de votre système. Pour afficher une liste de statistiques sur l'utilisation des inodes, telles qu'utilisé, gratuit et pourcentage utilisé, tapez la commande suivante:
sudo df -ih
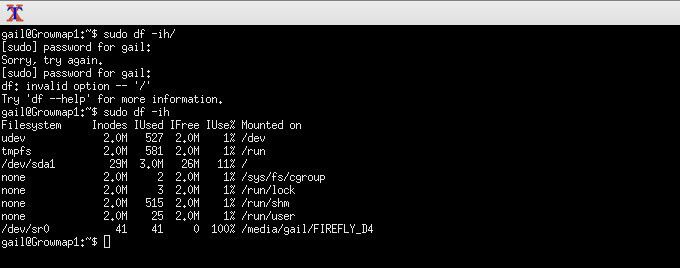
Autres façons d'utiliser les inodes
La façon dont les inodes fonctionnent sous Linux, il est impossible d'avoir des numéros d'inode conflictuels. Il n'est pas possible de créer un lien dur entre différents systèmes de fichiers. Cependant, vous pouvez utiliser des liens logiciels sur différents systèmes de fichiers. Vous pouvez supprimer les fichiers d'origine tout en conservant les données disponibles via un lien dur.
En supprimant un fichier, tout ce que vous avez fait est de supprimer l'un des noms pointant vers un numéro d'inode spécifique. Les données resteront jusqu'à ce que vous supprimiez tous les noms associés au même numéro d'inode. Les systèmes Linux sont mis à jour sans nécessiter de redémarrage du système en grande partie à cause du fonctionnement des inodes.
Un processus peut utiliser un fichier de bibliothèque en même temps qu'un autre processus remplace le même fichier par une nouvelle version mise à jour et crée un nouvel inode. Le processus en cours utilise toujours l'ancien fichier. La prochaine fois que vous utiliserez le même processus, il utilisera la nouvelle version.
Les utilisateurs n'interagissent pas directement avec les inodes, mais ils représentent un composant fondamental des structures de fichiers Linux.